Traditional RAG is powerful. Agentic RAG is RAG that thinks for itself.
If you’ve started building RAG pipelines, you’ve probably noticed a limitation: the system does exactly what you tell it. Ask a question, get relevant chunks, generate a response. Done.
That works great for straightforward queries. But what happens when the question is complex? Or when the first retrieval doesn’t return useful results?
That’s where Agentic RAG comes in.
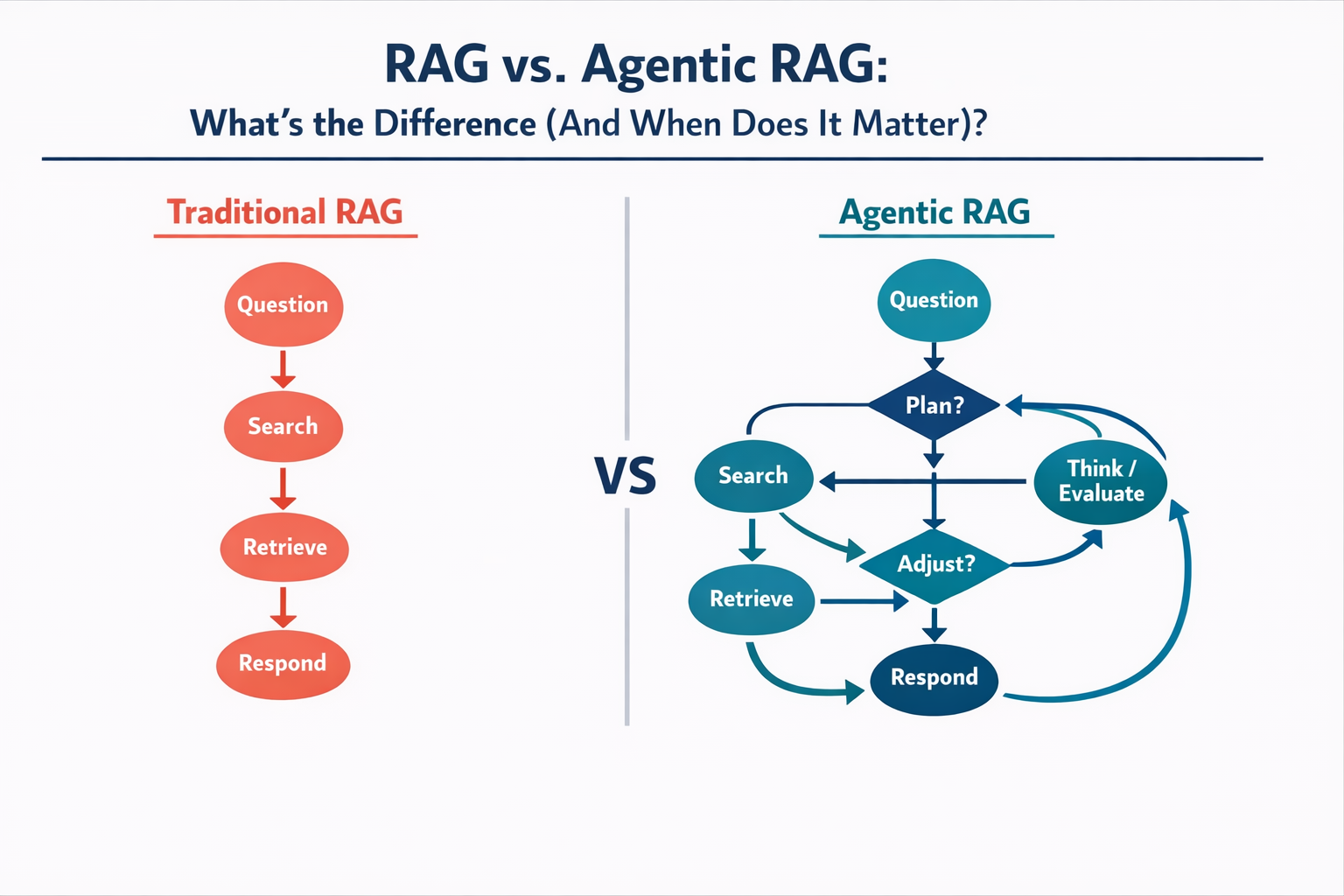
Traditional RAG: The Linear Approach
Standard RAG follows a predictable path:
- User asks a question
- System converts the question into an embedding
- Vector database returns the most similar chunks
- LLM generates a response using those chunks
It’s a one-shot process. The system retrieves once, generates once, and you get what you get. If the retrieved context wasn’t quite right, the response suffers.
Agentic RAG: RAG That Can Reason
Agentic RAG adds a layer of autonomy. Instead of blindly following a fixed pipeline, an AI agent decides how to answer the question.
Here’s what that looks like in practice:
🔹 Query reformulation: If the initial search returns weak results, the agent can rephrase the question and try again.
🔹 Multi-step retrieval: Complex questions get broken into sub-questions. The agent retrieves information for each part, then synthesizes everything.
🔹 Tool selection: Beyond just searching a vector database, the agent can decide to check a web API, run a calculation, or query a different data source entirely.
🔹 Self-correction: The agent can evaluate whether retrieved context actually answers the question before generating a response. If not, it keeps searching.
A Practical Example
Imagine someone asks: “How does our pricing compare to Competitor X, and what features justify the difference?”
Traditional RAG would search the vector database once, pull whatever chunks match best, and hope the answer is in there.
Agentic RAG might:
- First retrieve your pricing documentation
- Then search for Competitor X comparison notes
- Realize the competitive intel is outdated and flag that
- Pull feature documentation to explain differentiators
- Synthesize all of this into a coherent response
The agent is reasoning about what information it needs, not just pattern-matching keywords.
When to Use Which
Not every use case needs agentic complexity. Here’s a simple framework:
✅ Traditional RAG works well for:
- Single-topic questions with clear answers
- Well-structured knowledge bases
- High-volume, low-complexity queries (like FAQ bots)
- Situations where speed matters more than depth
✅ Agentic RAG shines for:
- Multi-part questions that span different topics
- Research tasks requiring synthesis across sources
- Scenarios where retrieval quality varies
- Use cases where “I don’t know” is better than a bad answer
Building Agentic RAG in n8n
The good news? n8n’s architecture actually lends itself well to agentic patterns. You can build loops, conditionals, and branching logic that let your workflow decide its next step based on results.
A basic agentic RAG setup might include:
- An initial retrieval node
- A “relevance check” using an LLM to evaluate the results
- Conditional branching: if relevant, generate response; if not, reformulate and retry
- A loop limit to prevent infinite searching
It’s more complex than a standard RAG pipeline, but the improvement in response quality for tricky questions can be significant.
The Bottom Line
Traditional RAG is like having a research assistant who follows instructions exactly. Agentic RAG is like having one who actually thinks about the best way to find the answer.
Start with traditional RAG to get the fundamentals down. Once those workflows are solid, agentic patterns become a natural evolution for handling more sophisticated use cases.
What’s Next?
Curious about building agentic workflows? Explore more AI automation guides at amayzing.ai.